Eh???
Some years ago I was working in a game project and I realize that I was using the std::vector a lot of times inside functions (for intermediate / temporary operations). Knowing that this wasn't so good for performance (because of the heaps allocation / memory fragmentation) I decided to implement a wrapper class "stack_vector" to use the stack instead of the heap. It is not a magic class nor something complicated, is just an array with a counter :). The most relevant thing here are the time measurements.
There were other solutions to the same problem:
- Change the stl for a better optimized lib.
- Use a custom allocator for the stl vector.
- Use an array.
Changing all the stl wasn't a fast solution, and using a custom allocator wasn't in my plans :p. No, the problem was that the main data I was using in these functions was trivial types (int, float, pointers, etc). So, using a stl still with a custom allocator will not be as performant as expected (or that was I thought in that moment). So I decided to implement this class.
Basically (3) is this, but with a counter and a simple interface :).
After 2 years (yes, 2 years) I decided to check if this class has any really improvement comparing to the std::vector or not, without taking into account the memory fragmentation, that was something that will for sure improve.
The stack_vector
The class is as simple as this (with some helper functions like a normal vector).
///
/// This class is intended to be used only for built in types that doesn't
/// requiere construction / destruction of the elements.
/// Obviously could be extended to support this, but not now :)
///
template <typename T, unsigned int MAX_SIZE = 64>
class stack_vector
{
// to avoid some issues when using this class we will make some checks here
// to ensure the user don't try to use this with objects that will create
// inconsistencies
static_assert((std::is_pointer<T>::value || std::is_trivial<T>::value),
"We can only use objects that has trivial default constructor "
"or are pointers or basic types");
public:
stack_vector() : m_size(0) {};
~stack_vector() {};
// ....
private:
T m_data[MAX_SIZE];
unsigned int m_size;
};
In this case the stack vector should know at priory the maximum size we will use, as any other normal array. This is not nice since sometimes we don't know how big it will be, but that could be solved using the Variable Length Array feature (C99) and passing the memory address to the class on the constructor (I copy and paste the same class and renamed to stack_vector2, lazy bastard!). Note also that this class is intended to be used only with trivial types (I'm not handling construction / destruction of the elements).
I also add some other methods to the interface that were utils when working on the project, but that doesn't matter to much.
I also add some other methods to the interface that were utils when working on the project, but that doesn't matter to much.
Measurements
I compile the sample test with 3 optimization levels (just using the -O flag):- Without flag.
- With -O2.
- With -O3.
And test for each case, different sizes (number of elements for the vectors): {50, 100, 200, 500, 1000, 5000}
I used g++ 4.9.2, old lovely dell vostro (intel dual core), linux.
The test routine that use the vector / stack_vector / stack_vector2 (VAL) are:
int
sampleCallHeap(void)
{
int result = 0;
std::vector<int> elements;
elements.reserve(NUM_COUNT);
for (int i = NUM_COUNT-1; i >= 0; --i) {
elements.push_back(i);
}
for (int i = 0; i < NUM_COUNT; ++i) {
result += elements[i];
}
return result;
}
int
sampleCallStack(void)
{
int result = 0;
stack_vector<int, NUM_COUNT> elements;
for (int i = NUM_COUNT-1; i >= 0; --i) {
elements.push_back(i);
}
for (int i = 0; i < NUM_COUNT; ++i) {
result += elements[i];
}
return result;
}
int
sampleCallStack2(int size)
{
int result = 0;
int mem[size];
stack_vector2<int> elements(mem);
for (int i = size-1; i >= 0; --i) {
elements.push_back(i);
}
for (int i = 0; i < size; ++i) {
result += elements[i];
}
return result;
}
As you can see, the 3 methods are pretty similar and very simple, we just create a vector, push all the elements, and then iterate over each one and sum the result into a variable.
The first test I did, the performance between all the versions were very similar, because malloc was always matching the perfect block for the std::vector (printing the address was always the same). So I decided to add some "random allocations" in between the calls (but not measuring the times of those) so the vector could or could not get the same address (like should happen in normal apps).
The timings I got calling N (=99999) times each of the test functions, for each different size (quantity of elements) and for each optimization level.
I will show for each case a bars graphic showing the three implementations: {std::vector, stack_vector, stack_vector2}, the stack_vector2 is the same than stack_vector but using the VAL feature. In the graphics the y axis is the time in seconds that took call N times each version, and the x axis the size of the vector. Also, a table containing the times for each case, and 2 more columns: Heap/Stack showing the performance (X gain) from the stack version comparing to the heap one, and Heap/Stack(VAL) comparing the heap and the VAL version (stack_vector2).
Without optimization

| Size | Heap | Stack | Stack (VAL) | Heap/Stack | Heap/Stack(VAL) |
| 50 | 0.3288 | 0.1696 | 0.1727 | 1.94 | 1.90 |
| 100 | 0.5142 | 0.2206 | 0.2373 | 2.33 | 2.17 |
| 500 | 2.0007 | 0.6031 | 0.7070 | 3.32 | 2.83 |
| 1000 | 3.8021 | 1.1257 | 1.2687 | 3.38 | 3.00 |
| 5000 | 18.2371 | 5.1559 | 5.9057 | 3.54 | 3.09 |
Optimization O2

| Size | Heap | Stack | Stack (VAL) | Heap/Stack | Heap/Stack(VAL) |
| 50 | 0.1432 | 0.1238 | 0.1247 | 1.16 | 1.15 |
| 100 | 0.1621 | 0.1273 | 0.1277 | 1.27 | 1.27 |
| 500 | 0.3385 | 0.1868 | 0.1821 | 1.81 | 1.86 |
| 1000 | 0.5632 | 0.2554 | 0.2516 | 2.21 | 2.24 |
| 5000 | 2.2400 | 0.8119 | 0.7838 | 2.76 | 2.86 |
Optimization O3
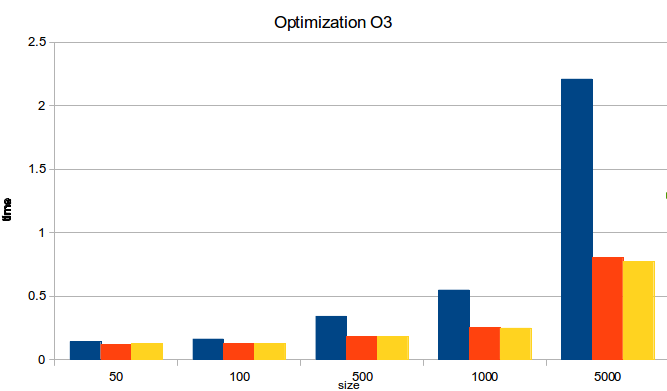
| Size | Heap | Stack | Stack (VAL) | Heap/Stack | Heap/Stack(VAL) |
| 50 | 0.1411 | 0.1207 | 0.1265 | 1.17 | 1.12 |
| 100 | 0.1628 | 0.1275 | 0.1283 | 1.28 | 1.27 |
| 500 | 0.3420 | 0.1841 | 0.1821 | 1.86 | 1.88 |
| 1000 | 0.5487 | 0.2525 | 0.2485 | 2.17 | 2.21 |
| 5000 | 2.2088 | 0.8040 | 0.7745 | 2.75 | 2.85 |
Conclusions
As we could see in the ugly graphics and nasty tables (sorry), the performance gain is not so much when we use the -O3 optimization level, the compiler do a lot of magic and the performance is almost the same. Bigger is the size of the vector (>~500) higher is the performance we gain, but note that using huge block of mem in the stack is not so recommended neither.
The main benefit I can see here, except the little performance gain (for ~100 elements), is minimizing the memory fragmentation that at the end will affect the overall of the app running time.
Note that this class was created a long time ago, just copy the old code into a new file but could be even more efficient (aligning the memory, checking if we can vectorize some operations, etc, but that will be done in 2 years :p).
Code
The test and code and everything is in github.
Salu.