What?
Some months (maybe a year) ago I was reading a book about game design patterns (from Bob Nystrom, very nice btw, I recommend to read it), and in one of the chapters about State pattern talking about "Observers", there was a particular problem of how to store the list of observers (the callbacks basically). The normal options are a list or vector, each one with the benefits and cons. List is """"less memory expensive"""", easy to remove elements at any point (maintaining the order), and also to add them but they are slower to iterate over the elements (jumping through pointers). The vectors, had the advantage that they are faster to iterate, but less efficient in terms of allocation / removing elements or inserting (not appending).
So, the idea, very basic idea, was to use list of chunks (list of arrays) to try to gain performance when iterating & decrease the memory usage.
So, as usual, after N years (N > 1, it seems to be a rule now), I decided to check if that idea had any kind of sense, was useful, or something, and, since the ticket in the book is still
open, I spend a little (really little) time on this. The code can be improved for sure and the performance as well..
chunk_list
The chunk_list as mentioned before, is basically a list<chunk> where the chunk is a fixed size array, and provides the normal operations to operate on it:
///
/// The class Chunk will be used to store a prefixed number of elements that
/// for now we will limit to be trivial constructible
///
template<typename T, unsigned int SIZE = 8>
class Chunk {
// to avoid some issues when using this class we will make some checks here
// to ensure the user don't try to use this with objects that will create
// inconsistencies
static_assert((std::is_pointer<T>::value || std::is_trivial<T>::value),
"We can only use objects that has trivial default constructor "
"or are pointers or basic types");
// support a small number for now
static_assert(SIZE < 256, "We maybe don't want chunks so big?");
public:
// default constructor & destructor, note we will not destroy the elements
// here
inline Chunk();
inline ~Chunk();
// add an element
inline void
push_back(T element);
// remove last element
inline void
pop_back(void);
// get X element
inline const T&
operator[](int index) const;
inline T&
operator[](int index);
// check if is full
inline bool
isFull(void) const;
// is empty
inline bool
isEmpty(void) const;
// check size
inline unsigned int
size(void) const;
// clear
inline void
clear(void);
private:
alignas (T) T m_data[SIZE];
short m_size;
};
Pretty the same than an array, maybe make no sense to implement it and use an array would be more than enough (+ counter).
I also implemented a list, very nasty list, that's why I called nasty_list, because is completely useless, but anyway, the important thing is that work for these tests: is single linked list (I didn't care measure insertion / removing elements, so just adding always at the end was more than fine).
/// define a simple list implementation only for this test
///
template<typename T>
struct Node {
T data;
Node* next;
Node() : next(0) {}
};
template<typename T, typename AllocT>
class nasty_list {
public:
// iterator, should go outside :(
//
template<typename T2>
class Iterator {
public:
/// ...
private:
Node<T2>* m_node;
};
friend class Iterator<T>;
public:
nasty_list(void) : m_first(0) {}
/// .... implementation ...
private:
Node<T>* m_first;
};
Well, very nasty, but works, at least for the tests, and is "correct" since the values given are the same than the stl ones (assuming stl is always true, always....?).
This nasty_lists supports some kind of "nasty_allocators", to allocate memory for the nodes, because I wanted to try heap / static memory, and check also the difference.
// AAAAAAAAAAAAHHHHHHHHHHHHHHHHHHHHHHHHHHHHHHH
// wth !
template<typename T>
struct HeapAllocator {
static T* allocate(void) {return new T;}
static void deallocate(T* t) {delete t;}
};
template<typename T, unsigned int SIZE>
struct StaticAllocator {
alignas(T) static T mem[SIZE];
static std::stack<T*> data;
static void
init(void)
{
for (unsigned int i = 0; i < SIZE; ++i) {
data.push(&(mem[i]));
}
}
static T* allocate(void)
{
T* r = data.top();
data.pop();
return r;
}
static void deallocate(T* t) {data.push(t);}
};
Look how nasty they are, even how bad performance could they have! but don't care, because I didn't measure the allocation / destruction of elements neither... Even when my soul doesn't feel fine doing nasty things, sometimes sh*** happens. Now the
chunk_list
template<typename T, typename NodeAlloc, unsigned int CSIZE = 8>
class ChunkList {
// helper typedefs
typedef Chunk<T, CSIZE> ChunkNode;
typedef nasty_list<ChunkNode, NodeAlloc> ListType;
public:
// iterator
//
template<typename T2>
class Iterator {
public:
/// ....
private:
Node<ChunkNode>* m_node;
int m_current;
};
friend class Iterator<T>;
public:
/// implementation
/// EXTRA METHOD
template<typename OP>
void applyToAll(OP& op);
private:
ListType m_list;
};
There is something important to note here, that I realized when I was implementing the class, and then I verified with the times I got: when we implement an iterator for this class, to iterate over all the elements (since that was the original focus of all this), it is not very trivial (for the compiler to optimize it) when checking the condition to move forward to get the next element on the chunk_list. This problem cause a big performance issue, since the original idea was to try to get the performance of iterating an array, but some times being interrupted by a jump (at least we can cache / fetch more elements at once). So, a second solution was provide the
applyToAll(...) method, that giving a functor (or whatever you want to call it), we apply it to all the elements, and this way, it is much more easier for the compiler so he knows how to optimize it.
auto beg = m_list.begin();
auto end = m_list.end();
while (beg != end) {
const ChunkNode& cn = *beg;
// here the compiler can optimize :)
for (int i = 0; i < cn.size(); ++i) {
op(cn[i]);
}
++beg;
}
Something also interesting and to take into account is that using
int instead of
unsigned int inside of the
for was twice faster. [The thing is that the compiler handles the integers differently than the unsigned int because of the overflow possibilities, in the case of the integers it gives a sh** so assumes that it will never happen => optimize. Also compiling with -
fwrapv use the same behavior for
unsigned int].
Measurements
Intro
As explained before, this tests are only focused in the performance related of iterating elements in the vector, list and chunk_list, but not inserting nor removing them, obviously the insertion in the chunk_list and removing them is faster than in a vector, but slower than a list.
Let's see how the code of the tests begin:
typedef nasty_list<int,NodeAllocator> ListT;
typedef ChunkList<int, NodeChunkAllocator, CHUNK_SIZE> ChunkListT;
ListT normalLists[LIST_COUNT];
ChunkListT chunkLists[LIST_COUNT];
std::list<int> stdlist[LIST_COUNT];
std::vector<int> vector[LIST_COUNT];
for (int j = 0; j < LIST_COUNT; ++j) {
for (int i = 0; i < ELEMENTS_PER_LIST; i++) {
normalLists[j].addElement(i);
chunkLists[j].addElement(i);
stdlist[j].push_back(i);
vector[j].push_back(i);
}
}
The types
NodeAllocator and
NodeChunkAllocator are defined at compile time, depending if "heap allocation" is set to true or not, and I use the different
nasty_allocators.
What I did, was fill the different lists (
LIST_COUNT,
at the end I just use 1), with
ELEMENTS_PER_LIST (=N) and then I started measuring the times, running this code:
double t1 = TimeHelper::currentTime();
for (unsigned int i = 0; i < ROUNDS; ++i) {
for (unsigned int j = 0; j < LIST_COUNT; ++j) {
auto beg = normalLists[j].begin();
auto end = normalLists[j].end();
for (; beg != end; ++beg) {
d1 += *beg;
}
}
}
double t2 = TimeHelper::currentTime();
const double normalListTime = t2 - t1;
In this particular example, was for the
normalLists (the nasty_list) defined above, and saving the total time I spend to read each element and sum it into a variable. I run the same piece of code
ROUNDS times (~9999999). I did the same for the
std::vector,
std::list,
nasty_list and
chunk_list (for the last case, I measured the iterator version and the functor version).
For the
chunk_list:functor version I use the next piece code:
struct OpSum {
int sum;
OpSum() : sum(0) {}
void operator()(int i) {sum+=i;}
} opSum;
t1 = TimeHelper::currentTime();
for (unsigned int i = 0; i < ROUNDS; ++i) {
for (unsigned int j = 0; j < LIST_COUNT; ++j) {
chunkLists[j].applyToAll(opSum);
}
}
t2 = TimeHelper::currentTime();
d4 = opSum.sum;
const double chunklListFunctorTime = t2 - t1;
Results
I run all the tests using the next hardware / soft / arch:
compiler: gcc version 4.9.2
OS: ubuntu linux - 32bits
Processor: Intel Core2 Duo CPU P8700 @ 2.53GHz × 2
Mem Ram: 4GB
(yes, prehistoric, but lovely dell still fighting!)
There are a lot of results, I measured the 5 different structures (std::list, nasty_list, std::vector, chunk_list iterator version, chunk_list functor version), with different compilation (optimization) flags and different data elements + chunk sizes, and allocator types.
I group all of them in 6 tables, divided in two groups: (A) using static allocator, (B) using dynamic allocator (new). Each group is divided in 3 sub groups: {No optimization flags, O3, O3 + vectorize flags}. For each sub group I measured the next combinations of:
chunk_size x
element_in_container: {1, 4, 8, 16} x {4, 8, 16, 32, 64}.
Since I didn't care the insertion / removal of the elements, the time difference between the groups (A) and (B) for iterating the elements in the containers could be considered the same, so I will only show one of them. Also, the difference between
O3 vectorize and
O3 is very similar so I also decided to show only one of them (
O3 - vectorize).
Lets see the tables:
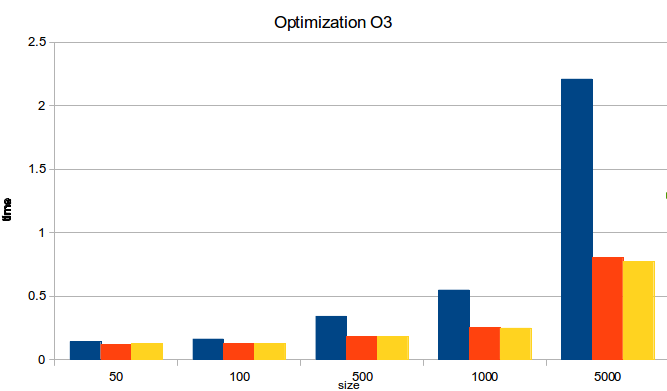
The table shows the 5 different containers (one each color) for each combination of a specific Chunk Size and N (number of elements that the containers has).
The Y axis shows the time in seconds it takes to iterate over all the elements of the container and sum them.
Comparing the performance of
chunk_list:functor against
std::list, nasty_list, std::vector I got the next
bests performance gains: 0.80X, 0.83X, 0.59X respectively (
std::list/chunk_list:functor, nasty_list/chunk_list:functor, std::vector/chunk_list:functor). Also, the next
worsts performance gains: 0.40X, 0.41X, 0.30X.
These "performance gains" are obtained getting the maximum / minimum times from all the cases.
Following the Optimized version:
In this case the performance gains comparing the
chunk_list:functor against the
std::list, nasty_list, std::vector were:
best: 3.12X, 3.63X, 2.28X.
worst: 0.74X, 0.82X, 0.42X.
Note again that this are getting the best/worst "times" between all the possibilities.
Conclusions
From what I see in the results, I think it worth it to make an effort and implement the
chunk_list in a cleaner and "performant" way since for almost all the cases the chunk_list performs very well in comparison with the list and even with the vector (COMPLETELY SENSELESS!!!!!!!!).
The
chunk_list is faster than the
std::vector, compiling with the next flags "
-std=c++11 -O3 -ftree-vectorize" the vector is slower, but adding the "
-march=native" compilation flag the performance of the vector is almost twice better than the
chunk_list.
Maybe, and only maybe, I will check this in deep, try to get the root cause of why the chunk_list is faster than a vector (could be something related with the
stl or using compile time sizes help the compiler to optimize even more...)... Next days / year / life maybe I will check it :p.
Salu